
Bienvenidos de nuevo a nuestra serie de blogs «Descifrando la «buena» IA», en la que utilizamos ejemplos reales del desarrollo de nuestro propio modelo de evaluación de ovocitos basado en IA para ilustrar los pasos clave necesarios para desarrollar un modelo de aprendizaje automático de alta calidad para el análisis de imágenes en medicina.
En nuestra anterior entrada del blog, le presentamos el apasionante mundo del aprendizaje automático (machine learning) y su aplicación práctica en la medicina reproductiva. Hablamos de la importancia de definir claramente la tarea específica que realiza el modelo y de las consideraciones esenciales para crear un conjunto de datos sólido que permita al modelo obtener buenos resultados en escenarios clínicos reales.
Continuando con nuestra serie, profundizamos en el desarrollo de un modelo de aprendizaje profundo (deep learning) para el análisis de ovocitos. En este artículo, exploraremos el siguiente paso crítico: Elegir la arquitectura de un modelo de aprendizaje profundo (deep learning).
Actualmente, muchas personas interactúan diariamente con la IA, pero cada tarea requiere modelos de IA desarrollados con diferentes diseños y tipos de arquitectura. Aquí exploraremos las mejores arquitecturas y las arquitecturas emergentes para el análisis de imágenes médicas.
Permanezca atento a nuestra próxima entrada en el blog, donde profundizaremos en el proceso de entrenamiento de un modelo de aprendizaje profundo (deep learning) y las consideraciones sobre su entrenamiento. Más adelante, cerraremos la serie desvelando los pasos finales de nuestro viaje por la IA: la evaluación del rendimiento del modelo y el continuo proceso de supervisión del rendimiento.
Al final de la serie, los profesionales clínicos tendrán una clara comprensión de los fundamentos de la «buena» IA y serán capaces de evaluar la calidad de los modelos de IA y su posible impacto en la práctica clínica.
ELEGIR UNA ARQUITECTURA DE MODELO DE APRENDIZAJE PROFUNDO (DEEP LEARNING)
Nuestro último artículo hablaba de la importancia de definir en primer lugar una tarea específica para el modelo, con el fin de garantizar que su arquitectura y diseño se seleccionan para abordar ese reto de la mejor manera posible. A medida que nos acercamos a la siguiente sección, recordemos que la tarea de nuestro modelo es evaluar imágenes de ovocitos para predecir si formarán un blastocisto.
Hay varios tipos de arquitecturas de modelos que pueden ayudar a resolver esta cuestión, por lo que parte del proceso de desarrollo de nuestro modelo consiste en experimentar con diferentes tipos de arquitectura para ver cuál es la que mejor funciona a la hora de realizar predicciones de blastocistos a partir de imágenes de ovocitos. También realizamos pruebas para ver si se pueden combinar varios tipos de arquitectura para obtener una mayor capacidad de predicción como modelo ensamblado.
Para ayudarle a comprender las distintas opciones de arquitectura disponibles para el desarrollo de nuestro modelo, vamos a hacer un breve repaso de la historia.
Los primeros modelos de clasificación de imágenes solían basarse en características extraídas a mano de las imágenes, como descripciones de textura, color o forma. A continuación, estas características se introducían en algoritmos tradicionales de aprendizaje automático (machine learning), como Random Forest o XGBoost (ambos basados en conjuntos de árboles de decisión), para clasificar las imágenes. Aunque estas arquitecturas básicas tuvieron cierto éxito en las tareas de clasificación más sencillas, requerían la identificación manual de las características y tenían dificultades para captar patrones de imagen complejos. Y lo que es más importante, el usuario tenía que ser capaz de identificar por sí mismo esas características, que en muchos casos no son obvias.
Aun así, dependiendo de la tarea específica que se vaya a realizar, la arquitectura ideal no tiene por qué ser siempre la opción más profunda o evolucionada. En algunos casos, estos métodos tradicionales siguen siendo candidatos valiosos para el diseño de modelos, ya que no requieren tantos datos como los modelos de aprendizaje profundo (deep learning).
Otra ventaja de estos modelos anteriores es que son «explicables«: el usuario sabe exactamente qué características de la imagen se han tenido en cuenta en la predicción. Por ejemplo, en uno de nuestros experimentos, estamos entrenando un modelo que utiliza características específicas que describen la morfología del ovocito, como la relación entre la zona pelúcida y el ooplasma.
Un avance rápido hasta el nacimiento de las redes neuronales convolucionales (CNN)…
Las CNN -que constituyen un componente clave de nuestro modelo– han supuesto una verdadera revolución en la clasificación de imágenes y se consideran la arquitectura más avanzada para analizar grandes cantidades de datos visuales.
Entre las principales tareas en las que destacan las CNN se incluyen:
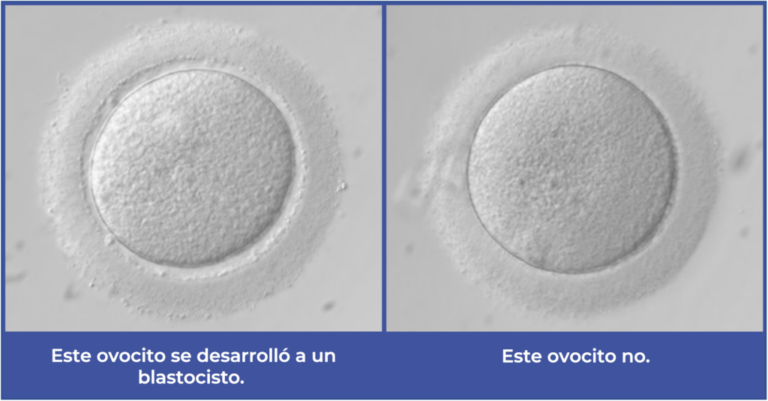
- • Clasificación de imágenes: La capacidad de diferenciar entre dos categorías de imágenes y asignarles el resultado esperado. Por ejemplo, en nuestra herramienta de IA, esto nos permite clasificar una imagen de un ovocito que formó un blastocisto frente a una imagen que no lo hizo.
- Como el resultado principal de nuestro modelo es la formación de blastocitos, esta capacidad es fundamental.
- • Detección de objetos: La capacidad de identificar qué objetos están presentes en una imagen y dónde se encuentran. Piense en la «detección de objetos» como en lo que el modelo ve en la imagen a un nivel general. A cada «objeto» se le asigna una etiqueta de clase y se anotan sus coordenadas dentro de la imagen. Para nosotros, esto es útil ya que puede detectar la ubicación del ovocito en un pocillo, garantizando que estamos capturando y analizando los datos correctos en la imagen.
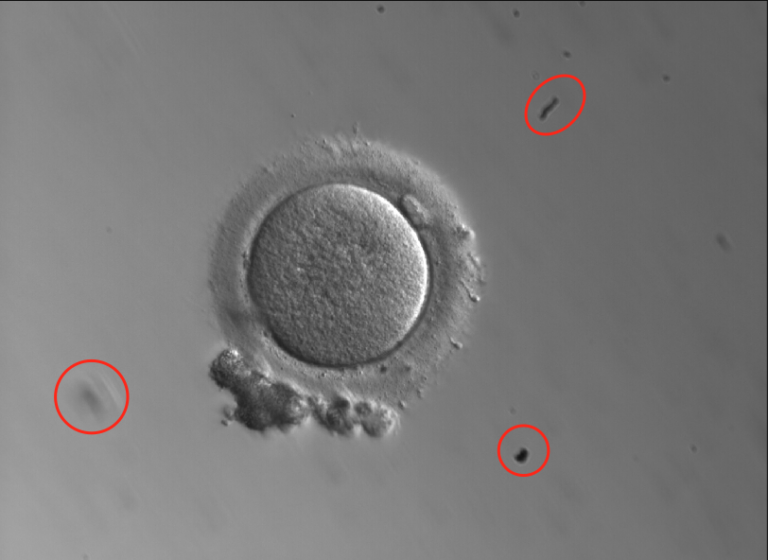
- Además, las imágenes pueden contener suciedad del microscopio u otros elementos propios de la configuración de un determinado laboratorio. Nuestro modelo necesita comprender qué parte de la imagen es el ovocito frente a otras partes de la placa o elementos, independientemente del lugar de la imagen en el que se encuentre el ovocito, para garantizar que centra su análisis en los píxeles que son relevantes para el resultado de las predicciones. Por último, esto también nos permite ser más precisos a la hora de comprender dónde se encuentran las características morfológicas específicas dentro del ovocito (cuerpo polar, zona pelúcida, etc.).
Ejemplo de imagen de un ovocito que contiene restos dentro de la placa.
- • Segregación semántica: Mientras que la detección de objetos adopta un enfoque macro del análisis de imágenes, la segregación semántica adopta un enfoque micro. Se trata de la capacidad de etiquetar cada píxel individual de una imagen como perteneciente a una de las clases identificadas durante el ejercicio de detección de objetos (por ejemplo, separar ooplasma frente a espacio perivitelino frente a zona pelúcida).
- • Manejo de grandes cantidades de datos: Cada píxel de una imagen es un punto de datos que puede utilizar una CNN. ¡Algunas imágenes de alta calidad de nuestra base de datos tienen más de 19 millones de píxeles!
- Los modelos de CNN tienen una serie de trucos que les permiten aprovechar la estructura espacial de las imágenes para reducir la complejidad del modelo y para aprender características visuales significativas de los datos. Uno de los principales ejemplos es el uso de algoritmos de entrenamiento eficientes (Efficient Training Algorithms) basados en el gradiente estocástico descendente, un algoritmo que ha demostrado ser muy eficaz para entrenar modelos a gran escala con grandes volúmenes de datos.
- Dado que los modelos CNN realizan la detección automática de características en función de su importancia para una predicción precisa, pueden encontrar nuevas características que el usuario desconoce para realizar mejores predicciones.
Los modelos CNN suelen requerir un número masivo de datos para lograr una gran precisión y generalización en comparación con las técnicas clásicas de aprendizaje automático. En los casos en los que el conjunto de datos especializado no incluye millones de imágenes, un modelo CNN puede preentrenarse primero en un conjunto de datos grande y más general, como ImageNET, y luego afinarse en un conjunto de datos de imágenes más pequeño que sea directamente relevante para la tarea del modelo (por ejemplo, imágenes de ovocitos). Esto se denomina aprendizaje por transferencia y ha demostrado ser una técnica muy útil y popular. En la fase de preentrenamiento, el objetivo es acostumbrar al modelo a clasificar amplias categorías de imágenes mediante el reconocimiento de diferentes contornos, texturas u otras características sencillas. Más adelante, cuando se introduce el conjunto de datos más pequeño y específico de la tarea, el modelo transfiere ese conocimiento de clasificación más amplio para ayudar a centrar su entrenamiento más específico.
Este ejemplo deja claro que cualquier modelo de clasificación de imágenes puede haberse entrenado con millones de imágenes si se incluye el conjunto de datos de preentrenamiento. Sin embargo, a la hora de evaluar distintos modelos para su clínica, es importante conocer el tamaño del conjunto de datos específico para la tarea.
Por ejemplo, nuestro modelo se entrenó y testeó con más de 120.000 imágenes de ovocitos, el mayor conjunto de datos de su clase, para centrarlo en la identificación de las características que contribuyen a la formación del blastocisto.
Durante años, las CNN han sido la arquitectura preferida para tareas de clasificación de imágenes y detección de objetos, pero otras arquitecturas están ganando terreno rápidamente en este ámbito, sobre todo los Transformadores (Transformers).
ChatGPT, Siri (Apple), Google Translate y Alexa (Amazon) funcionan con modelos basados en transformadores. Las arquitecturas de transformadores se desarrollaron originalmente para tareas de procesamiento del lenguaje natural (NLP), como la comprensión y generación de texto. Sin embargo, los investigadores han encontrado formas creativas de aplicarlas a tareas de análisis de imágenes, con ventajas únicas sobre las CNN.
Las CNN se centran primero en comprender los microdetalles importantes de una imagen y luego la exploran en busca de patrones en esos detalles. Los transformadores adoptan un enfoque aparentemente inverso: evalúan toda la imagen a la vez y la dividen en fragmentos más pequeños para comprender las relaciones entre ellos y los objetos que contienen. Este enfoque holístico permite a los transformadores manejar un número variable de objetos en una imagen, captar un contexto más global y comprender mejor las dependencias de largo alcance entre objetos, lo que les ayuda a detectar objetos y clasificar imágenes con precisión.
Se ha comprobado que los transformadores de visión (ViTs) y los transformadores de detección (DETRs) alcanzan un rendimiento comparable o incluso superior al de las CNNs en tareas de clasificación de imágenes a gran escala y de detección de objetos, respectivamente. Ambas arquitecturas siguen teniendo sus puntos fuertes y se utilizan en función de los requisitos específicos de la tarea en cuestión.
Nuestro equipo está siempre experimentando con las últimas evoluciones en arquitecturas de aprendizaje profundo para desarrollar nuevas versiones de nuestro modelo de IA que mejoren continuamente nuestro rendimiento. Estas diferentes arquitecturas pueden combinarse en un modelo combinado para mejorar el poder predictivo de nuestras herramientas.
Los nuevos planteamientos que demuestran una posible mejora del modelo se prueban y evalúan cuidadosamente antes de incorporarlos a nuestro modelo. Todas las versiones que se utilicen en su clínica a través de nuestro software han sido validadas como el modelo con mejor rendimiento hasta el momento.
Al igual que en la creación de un gran equipo en su clínica donde cada miembro contribuye con sus habilidades especiales, los modelos ensamblados pueden reunir lo mejor de las diferentes arquitecturas de clasificación y detección de imágenes para proporcionar predicciones más sólidas del potencial reproductivo de un ovocito.
Suscríbase a nuestra newsletter para recibir información sobre los últimos avances en fertilidad